Com o crescimento de um projeto de software, o nível de complexidade também aumenta. Para isso, temos padrões que nos auxiliam no isolamento de código e na estruturação do projeto, seja facilitando o entendimento ou melhorando a forma como acessamos ou fazemos algo.
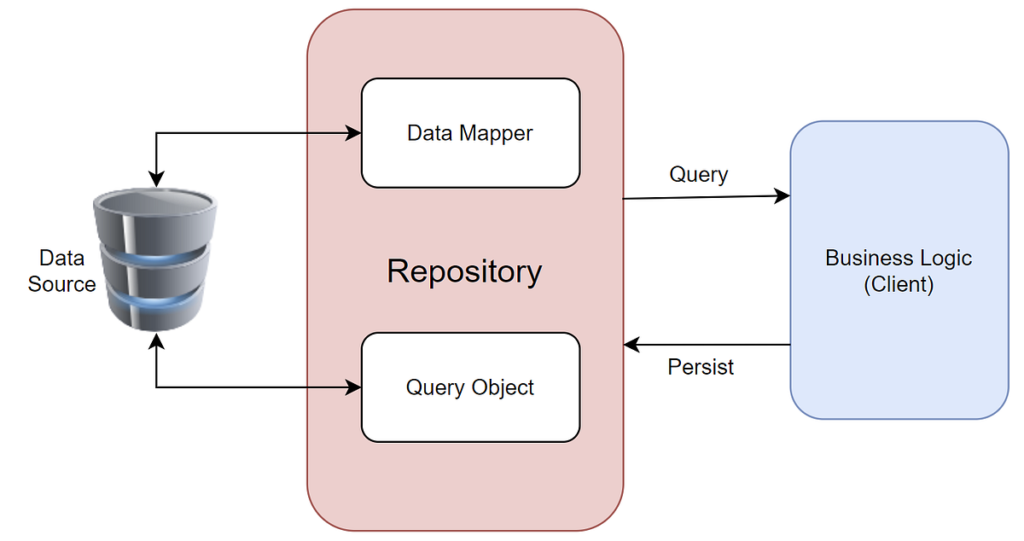
Hoje, venho mostrar para vocês o Repository Pattern, um padrão de projeto cuja principal finalidade é separar a lógica de acesso a dados da lógica de negócios, promovendo um design mais limpo e organizado nas aplicações. Em resumo, a utilização desse pattern contribui para o isolamento da camada de acesso a dados (DAL) com a camada de negócio, também conhecida como camada de domínio.
 Fonte: https://miro.medium.com/v2/resize:fit:1200/0*dLN2R69sE4BE2kT4.png
Fonte: https://miro.medium.com/v2/resize:fit:1200/0*dLN2R69sE4BE2kT4.png
Seu funcionamento é bem simples, ele isola a lógica de acesso a dados da lógica de negócios, permitindo que a aplicação se comunique com uma interface de repositório em vez de diretamente com a fonte de dados. De forma detalhada:
- Interface do Repositório: Definimos uma interface (ou classe base) que declara os métodos que o repositório deve implementar. Isso inclui operações básicas como adicionar, atualizar, remover e buscar entidades.
- Implementação do Repositório: Criamos uma ou mais implementações concretas dessa interface. Essas implementações contêm a lógica específica para acessar a fonte de dados (banco de dados, APIs, etc.).
- Entidades/Modelos: As entidades são classes que representam os dados manipulados pela aplicação. Elas geralmente correspondem a tabelas em um banco de dados relacional ou a coleções em um banco de dados NoSQL.
- Serviços: Os serviços contêm a lógica de negócios da aplicação. Eles utilizam o repositório para realizar operações sobre as entidades. O serviço não precisa saber como os dados são persistidos ou recuperados, apenas como utilizar a interface do repositório.
- Injeção de Dependências: Em muitas arquiteturas, os repositórios são injetados nos serviços usando injeção de dependências. Isso facilita a substituição do repositório por uma implementação diferente, se necessário, e facilita os testes unitários.
Como principais benefícios desse pattern, podemos citar:
- Isolamento da Camada de Dados: Prover uma camada de abstração entre a aplicação e a fonte de dados (banco de dados, serviços externos, etc.), permitindo que a lógica de negócios da aplicação interaja com essa camada sem precisar saber os detalhes de como os dados são persistidos ou recuperados.
- Facilitação da Manutenção e Evolução: Com essa separação, mudanças na lógica de acesso a dados (como alterações no banco de dados ou mudanças na forma como os dados são armazenados) podem ser feitas no repositório sem impactar diretamente a lógica de negócios.
- Testabilidade: Facilitar a escrita de testes unitários, permitindo que repositórios sejam substituídos por mocks ou stubs durante os testes, sem afetar a lógica de negócios.
- Reutilização de Código: Promover a reutilização de código ao centralizar a lógica de acesso a dados em um único lugar, evitando duplicação de código em diferentes partes da aplicação.
- Organização e Clareza: Melhorar a organização do código ao dividir responsabilidades, tornando o código mais legível e entendível.
Vamos para algo mais prático, como implementar esse pattern? Existem várias formas, seja através de interfaces com o princípio de inversão de dependência possibilitando a injeção de dependência dessa interface, ou apenas uma classe simples. Nesse artigo, abordaremos o mais simples para que você, de fato, compreenda o funcionamento desse padrão.
Primeiro, vamos ver os diretórios do nosso projeto:
my_app/
|-- repositories/
| |-- user_repository.py
|-- models/
| |-- user.py
|-- services/
| |-- user_service.py
|-- main.py
No nosso models/, definimos a classe User, que representa o modelo de dados.
class User:
def __init__(self, user_id, name, email):
self.user_id = user_id
self.name = name
self.email = email
def __repr__(self):
return f"User(id={self.user_id}, name={self.name}, email={self.email})"
Dentro de repositories/, mplementamos o repositório que lida com a persistência dos dados dos usuários
class UserRepository:
def __init__(self):
self.users = {} # Simulando um banco de dados em memória
def add_user(self, user):
self.users[user.user_id] = user
def get_user_by_id(self, user_id):
return self.users.get(user_id)
def remove_user(self, user_id):
return self.users.pop(user_id, None)
def list_users(self):
return list(self.users.values())
Dentro de services/, criamos um serviço que utiliza o repositório para realizar operações de negócio.
from repositories.user_repository import UserRepository
from repositories.user_repository import UserRepository
from models.user import User
class UserService:
def __init__(self, user_repository):
self.user_repository = user_repository
def create_user(self, user_id, name, email):
user = User(user_id, name, email)
self.user_repository.add_user(user)
return user
def get_user(self, user_id):
return self.user_repository.get_user_by_id(user_id)
def delete_user(self, user_id):
return self.user_repository.remove_user(user_id)
def list_all_users(self):
return self.user_repository.list_users()
Por fim, no nosso main.py, u samos o serviço no ponto de entrada da aplicação.
def main():
user_repository = UserRepository()
user_service = UserService(user_repository)
# Criando usuários
user_service.create_user(1, "Alice", "alice@example.com")
user_service.create_user(2, "Bob", "bob@example.com")
# Listando usuários
print("Todos os usuários:", user_service.list_all_users())
# Obtendo um usuário específico
print("Usuário com ID 1:", user_service.get_user(1))
# Removendo um usuário
user_service.delete_user(1)
print("Todos os usuários após remoção:", user_service.list_all_users())
if __name__ == "__main__":
main()
Provavelmente, se você já trabalhou com linguagens como Java, C#, PHP ou etc, deve ter visto uma forma diferente de se implementar, e não tem problema, pois ambas as implementações seguem a ideia principal desse pattern, que é isolar a camada DAL da camada de negócio.